Wether it has something to do with the current Terror Alert level or with a renewed surge of isolationism I don’t know, but my foreign ass no longer seems to be welcome below the Dot-US TLD. Never mind that almost all of my visitors are American. Or that my dot-US websites are hosted at US-based NearlyFreeSpeech. Or are my ties to the states sufficient that I just need to deliver the proof?
So, what happened? Yesterday, I got a mail from .US Nexus, forwarded by GoDaddy. It wasn’t the worst that GoDaddy billed me $9.95 for … forwarding a mail to me. What was bad was the mail that they forwarded:
From: “cctldhelp@godaddy.com” <cctldhelp@godaddy.com>
To: bigsmoke@gmail.com
Date: Jul 19, 2007 5:16 PM
Subject: [FWD: {Registry#542-209} .US NEXUS COMPLIANCE BIGSMOKE.US]Dear Rowan Rodrik van der Molen,
Please see the Nexus Compliance Notice below from Neustar.
Regards,
Domain Services
Subject: {Registry#542-209} .US NEXUS COMPLIANCE BIGSMOKE.US From: “.US Nexus” <nexus-compliance@neustar.us>
Date: Wed, July 18, 2007 3:46 pm
To: “cctldhelp@godaddy.com” <cctldhelp@godaddy.com>
Dear Go Daddy,
Please send the following verbiage to your customer.
Thank-You
Andrea
Neustar RegistriesDear Rowan,
As you may be aware, in November 2001, the United States Department of Commerce (“DOC”) selected NeuStar, Inc. (“NeuStar”) to be the Administrator of the .US top-level domain (“usTLD”), the official top-level domain for the United States of America. As Administrator of the usTLD, NeuStar has agreed to perform random “spot checks” on registrations in the usTLD to endure that they comply with the usTLD Nexus Requirements which can be found at http://www.neustar.us/policies/docs/ustld_nexus_requirements.pdf (“Nexus Requirements”).
Our records indicate that you are the registrant of the domain name BIGSMOKE.US.
On July 18, 2007, this domain name was selected for Nexus revalidation and confirmation. According to the information you provided with your registration of these Domain Names, you indicated that you qualify under:
Category 1 – You are a US citizen or permanent resident
As part of our verification process, we ask that you provide to us by no later than ten (10) days after the date set forth above, a written response describing how you qualify under the above Nexus category.
In addition, please verify that the name-servers that you have selected to use are also physically located within the United States as required by the Nexus Requirements.
In some instances, we may request additional documentary evidence from you to demonstrate that you meet the Nexus requirements.
You should be aware that if you either (i) do not respond within the ten (10) days, or (ii) are unable to adequately explain or demonstrate through documentary evidence that you meet any of the Nexus Requirements, NeuStar may issue a finding that your entity or organization has failed to meet the Nexus Requirements. Upon such a finding, you will then be given a total of ten (10) days to cure the US Nexus deficiency. If you are able to demonstrate within ten (10) days that your entity or organization has remedied such deficiency, you will be allowed to keep the domain name. If, however, you either (i) do not respond within the ten (10) days of such a finding of noncompliance, or (ii) are unable to proffer evidence demonstration compliance with the Nexus Requirements, the domain name registration will be deleted from the registry database without refund, and the domain name will be placed into the list of available domain names.
Thank you for your cooperation in this matter. Please let us know if you have any questions.
Kind Regards
Andrea
.US Customer Support
___________________________________________NeuStar
.US America’s Internet AddressEmail: support.us@neustar.us
Address: Loudoun Tech Center
46000 Center Oak Plaza
Sterling, VA 20166 USA
Web Site: www.neustar.us
___________________________________________This transmission (the e-mail and all attachments) is confidential and intended solely for the use of the addressee(s). If you have received this transmission in error, please notify the sender by reply and delete this transmission immediately. Any unauthorized distribution, or copying of this transmission, or misuse or wrongful disclosure of information contained in it, is strictly prohibited. The information contained in this document is provided on an as-is basis and does not constitute a binding legal contract or receipt for services. While this information is believed to be substantially correct, it is not intended to be substituted for appropriate legal counsel.
If you have any questions related to intellectual property rights, copyrights, service marks, whether in common use or legally registered, please contact your legal counsel. No statement made, printed, or otherwise disseminated by NeuStar or any of its employees, contractors, sub-contractors, web site, or interactive voice response system should be considered in any way legal or other advice.
I was left a little confused and hoped that, maybe, Andrea could shed some light on my ignorance.
From: Rowan Rodrik van der Molen <rowan@bigsmoke.us>
To: nexus-compliance@neustar.us
Date: Jul 19, 2007 6:40 PM
Subject: Re: [FWD: {Registry#542-209} .US NEXUS COMPLIANCE BIGSMOKE.US]Dear Andrea,
When registering my bigsmoke.us domain, I actually did so because I qualify according to Category 3, not Category 1. I qualify because my .US websites are hosted at a US hosting provider (NearlyFreeSpeech) and donations to my website are processed by a US company (Paypal). Also, advertisements are served by Google inc.
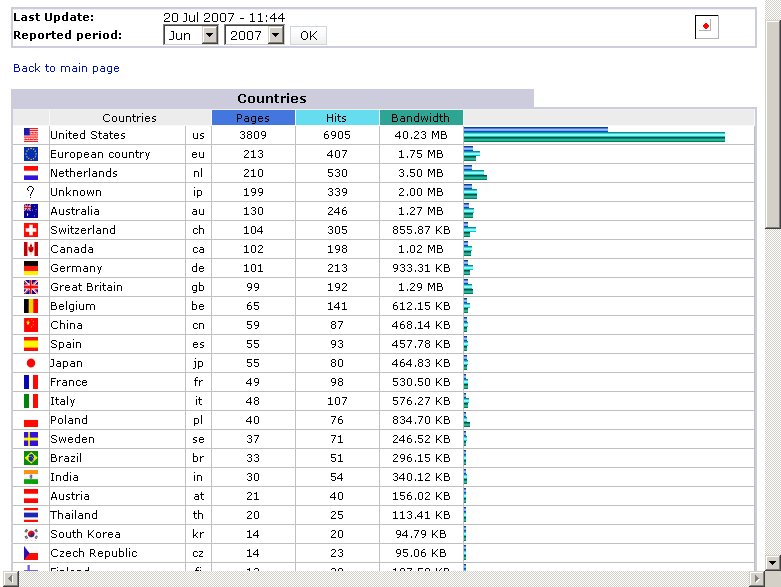
Most of my visitors are US residents because my websites are targeted at an American audience. (Detailed statistics about this can be obtained from http://www.bigsmoke.us/awstats.cgi) I’d like to note that my website is a valuable resource to many American web developers, database developers and system administrators. Because most of my visitors are American, it would be Americans which would be harmed most if I where to loose my dot-us domain.
As can be inferred from the Whois info, the nameservers for my domain are located at the same US hosting company as where my .us websites are hosted.
If you require any additional information, I’d be more than willing to send it to you. I wouldn’t have registered this domain if I hadn’t been convinced of the legality of such an action.
Thank you for your time,
Rowan
Today, I got a friendly reply from Andrea:
From: “.US Nexus” <nexus-compliance@neustar.us>
To: Rowan Rodrik van der Molen <rowan@bigsmoke.us>
Cc: “cctldhelp@godaddy.com” <cctldhelp@godaddy.com>
Date: Jul 20, 2007 6:31 AM
Subject: RE: {Registry#542-209} .US NEXUS COMPLIANCE BIGSMOKE.USRowan,
Your domain information in WHOIS shows you are a Category 1. That would indicate that you are a United States citizen. You will need to provide your current US drivers license to prove how you meet the .US Nexus guideline.
If you are doing legitimate business within the United States you will need to correct your domain information to reflect the .US WHOIS.
Below are two categories of which you may fall into.
C31: A foreign entity or organization that has a bona fide presence in the United States of America or any of its insular areas who regularly engages in lawful activities (e.g., sales of goods or services or other business, commercial or non-commercial, including not-for-profit relations in the United States).
C32: Entity has an office or other facility in the United States
If you claim C31, you will need to provide to us documentation in the form of a certificate of corporation or the ability to provide not only the sales of goods but to prove those sales are with United States residents/companies.
If you claim C32, you will need to provide documentation that proves you have and office or facility in the United States.
The information that you have provided in your e-mail is not sufficient enough to prove you meet the Nexus requirements.
Kind Regards,
Andrea
.US Customer Support
___________________________________________NeuStar
.US America’s Internet AddressEmail: support.us@neustar.us
Address: Loudoun Tech Center
46000 Center Oak Plaza
Sterling, VA 20166 USA
Web Site: www.neustar.us
___________________________________________[The same interesting legalese as in the previous mail from .US Nexus …]
All good and well, but all I can extract from this communication is that I need to change the category at GoDaddy. I still don’t understand if I’m eligible to have an dot-US domain (which I recently extended (with US dollars), by the way). Based on the usTLD Nexus Requirements I’d assume that I qualify for a dot-US domain under Category 3, A foreign entity or organization that has a bona fide presence in the United States of America
or any of its possessions or territories.
In full, the requirements for Category 3 are as follows:
Nexus Category 3
A foreign entity or organization that has a bona fide presence in the United States of America or any of its possessions or territories.
- Applicant must state country of citizenship.
- Applicant must also (1) regularly engage in lawful activities (sales of goods or services or other business, commercial or non-commercial including not-for-profit activities) in the United States; or (2) maintain an office or other property within the United States.
Category 3 Nexus Certification
Prospective Registrants will certify compliance with Category 3 Nexus based upon substantial lawful contacts with, or lawful activities in, the United States.
Factors that should be considered in determining whether an entity or organization has a bona fide presence in the United States shall include, without limitation, whether such prospective usTLD domain name Registrant:
- Regularly performs lawful activities within the United States related to the purposes for which the entity or organization is constituted (e.g., selling goods or providing services to customers, conducting regular training activities, attending conferences), provided such activities are not conducted solely or primarily to permit it to register for a usTLD domain name and are lawful under the laws and regulations of the United States and satisfy policies for the usTLD, including policies approved and/or mandated by the DoC;
- Maintains an office or other facility in the United States for a lawful business, noncommercial, educational or governmental purpose, and not solely or primarily to permit it to register for a usTLD domain name.
Apart from the fact that these days The Netherlands can be considered American territory, you’d think I neatly fit the requirements for C31, since I perform the following lawful activities in the United States:
- I regularly pay my US hosting provider, NearlyFreeSpeech.Net, US dollars to host my US website.
- I pay my US domain registar (Wild West Hosting / Go Daddy) in US dollars for my domain.
- These and other services are paid for using Paypal, which, last time I checked, was still a US company.
- Advertisements on my regular website are served by Google, which, also, is a US company. This also means I get income from … a US company.
- Almost all my visitors are American as I write for an English speaking audience.
I’m not sure if any of this is lawful
. Perhaps, being active in America in any other way than singing the national anthem and waving a flag is illegal these days. But, I’d say that an English resource which is heavily linked to and visited by thousands (mostly Americans) should somehow be able to fit these requirements. After all, how are the interests of the American people served if a .US website is taken off-line because it’s run by a foreigner from overseas? Are my American visitors supposed to be happy if their links stop working and the top search results for some of their searches suddenly disappear?
I guess that’s not the point and I’m hoping that one of my visitors can help me figure out what I should send to Andrea to make her happy to let me keep the domain for which I’ve paid good USD.


Recent Comments