There is a bug in Konsole with tmux: lines often aren’t cleared properly. To fix, put this in tmux.conf:
set -as terminal-overrides ',*:indn@'
Smokes your problems, coughs fresh air.
There is a bug in Konsole with tmux: lines often aren’t cleared properly. To fix, put this in tmux.conf:
set -as terminal-overrides ',*:indn@'
Just some example code for an nginx maintenance page:
server { listen 80; listen 443 ssl; server_name www.example.com; ssl_certificate_key /etc/ssl/temp/wildcard.example.com.key; ssl_certificate /etc/ssl/temp/wildcard.example.com.fullchainchain.crt; location = /503.html { root /srv/http/maintenance/; } location = /logo.png { root /srv/http/maintenance/; } location / { if ($remote_addr != 1.2.3.4) { error_page 503 /503.html; return 503; } } }
This is an interesting case. I made a sound system for a friend in 2012. In it is a soft-starter, that engages the heavy transformer through a ballast, so that the fuse doesn’t trip. This is it:

Up until today, I never knew he had to replace the fuse a few times a year. The reason I found out now, is because the amp wouldn’t start anymore; it would always blow a fuse. So, I was called in to repair.
This is the relay now, with charred contacts:

One initial thought of course is that the amp was turned off/on super quick, so the relay didn’t have time to disengage, subsequently connecting the mains directly to the unstabilized transformer. However, my softstarter design can handle quick off-on (although not super quick, I just tested), and he was adamant that it often happened after hours of off-time, and being careful not to bounce the switch.
My theory is that the mains AC sometimes arced over the relay on turn-on, so that the ballast would be bypassed, obviously blowing a fuse. This arcing slowly wore out the contacts, and probably made it more susceptible, ultimately resulting in always arcing. However, I use the exact same design in my own builds, and I never have this problem.
The relay is rated for 250 Vac, 30 Vdc. But perhaps with the mains in the right position, the transformer acts as a fly-back.
Interestingly, the relay contacts still read near-zero Ohms, and there is little to no voltage over it with when I test it with my 30V, 3A bench supply.
I now replaced it with a nifty relay (Amplimo LRZ) that has a wider gap, and tungsten pre-contact:

I’ll report back in a year how it held up.
2024-03-20. This blog post was originally posted six years ago—on April 23, 2018—on the blog of my then-employer Ytec, at https://ytec.nl/blog/why-mature-erp-exact-should-use-snapshot-isolation-their-rdbms/. Some former (or subsequent) colleague of mine must however have missed the memo that Cool URLs Don’t Change and my blog post—actually their whole blog—doesn’t seem to have survived their latest website overhaul. Luckily, I could still retrieve my article as it was from the Internet Archive’s Wayback Machine, and now I’m posting it here, because even if Ytec no longer cares about my content, I do still think that the below remains worthwhile.
A client of ours [Ytec] has over the years grown into an ERP (Exact Globe) that stores all its data in an MS SQL Server. This by itself is a nice feature; the database structure is stable and documented quite decently, so that, after becoming acquainted with some of the legacy table and column names (e.g. learning that frhkrg really means ‘invoice headers’), information can often be retrieved easily enough. Indeed, this is very useful, for example when connecting the ERP (as we did) to a custom-made webshop, or when setting up communications to other systems by EDI.
However, contrary to what you’d expect with all the data stored in a big-name SQL server, the data can at times be difficult to access due to deadlocks and other locking time-outs. A lot of time has gone into timing various integration tasks (SSIS, cron jobs and the like) such that they do not interfere with each other, while most of these tasks only read from the database, with the exception of a few task-specific tables (which will rarely cause locking issues).
There are some slow functions and views in the database, but it’s running on such a powerful server (24 cores, 200GB RAM) that this really ought not to be a problem. Yet it is, and it continues to be. And the problem can hardly be solved by further optimizations or by throwing yet more iron at it. The problem could be solved by turning on snapshot isolation.
Coming from a PostgreSQL background, I was quite surprised to find that snapshot isolation is not turned on by default in MS SQL Server. In Postgres it cannot be turned off (due to its multiversion concurrency control architecture). And why would you want to?
Without snapshot isolation, what you have is a situation where reads can block writes, except when the transaction isolation level is READ UNCOMMITTED, which isn’t even supported by PostgreSQL (which treats READ UNCOMMITTED as READ COMMITTED). Except for heuristic reporting, READ UNCOMMITTED is best avoided since it allows dirty reads, of uncommitted operations that may well be rolled back later. That’s why the default transaction isolation level in MSSQL, MySQL and PostgreSQL is READ COMMITTED. Sometimes, there are stricter requirements: for example, that the data used in the transaction should not change except from within the transaction. Such could be guaranteed by using the strictest transaction isolation level: SERIALIZABLE. Somewhere in between READ COMMITTED and SERIALIZABLE is REPEATABLE READ. Anyway, the take-home message is that stricter transaction isolation levels generally require more aggressive locking.
Suppose I have an EDI task that has to export shipping orders to a warehouse. In Exact, these orders can be found by querying the frhkrg table (with invoice header lines):
BEGIN TRANSACTION select_unexported_invoices; -- SET TRANSACTION ISOLATION LEVEL READ COMMITTED; -- is implied SELECT faknr -- invoice number FROM frhkrg WHERE fak_soort = ‘V’ AND NOT EXISTS ( SELECT * FROM invoices_exported WHERE invoice_number=frhkrg.faknr )
Besides the interesting table and column names, this select statement is straightforward enough. What caught me by surprise, as a long time PostgreSQL user, is that this transaction can be blocked by an innocuous update on the frhkrg table in a parallel transaction. Yes, with snapshot isolation off, writes can block reads, even if the the transaction does not even require repeatable reads.
This behaviour is easy to replicate:
CREATE DATABASE Ytec_Test; USE Ytec_Test; --- -- Create test table with test data and index -- CREATE TABLE locking_test ( id INT PRIMARY KEY, col1 VARCHAR(32) NOT NULL, col2 VARCHAR(32) NOT NULL, col3 VARCHAR(32) NOT NULL ) ; INSERT INTO locking_test (id, col1, col2, col3) SELECT 1, 'Aap', 'Boom', 'A' UNION ALL SELECT 2, 'Noot', 'Roos', 'B' UNION ALL SELECT 3, 'Mies', 'Vis', 'C' UNION ALL SELECT 4, 'Wim', 'Vuur', 'D' ; CREATE NONCLUSTERED INDEX bypass_lock ON locking_test (col1) INCLUDE (col2, id) ;
With the test data set-up, it’s easy to lock a read operation:
BEGIN TRANSACTION WRITE1; UPDATE locking_test SET col1 = 'Aap-je' WHERE id=1;
As long as transaction WRITE1 is open, most selects will be blocked (except one, which uses the index exclusively):
BEGIN TRANSACTION READ1; -- SET TRANSACTION ISOLATION LEVEL READ COMMITTED -- is implied SELECT id FROM locking_test; -- WITH (READCOMMITTED) -- is implied (as also below) -- Time-out SELECT id, col2 FROM locking_test WHERE col3='D'; -- with a non-indexed column in the predicate -- Time-out SELECT id, col3 FROM locking_test WHERE col1='Aap'; -- with a non-indexed column in the select list -- Time-out SELECT id,col2 FROM locking_test WHERE col1='Noot'; -- with only indexed columns -- id col2 -- 2 Roos
One trick that can be glimpsed from this example is that you can use indices to bypass locks, but only to the extent that you’re not trying to select a row that is currently being locked. The following doesn’t work when WRITE1 is open:
BEGIN TRANSACTION READ2; SELECT id FROM locking_test WHERE col1='Aap'; -- doesn't work
Another possibility to partially work around aggressive locking is to use the table-hint READPAST:
SELECT id FROM locking_test WITH (READPAST) ORDER BY id; -- id -- 2 -- 3 -- 4
But, as you can see, this is limited in its applicability, since the locked row won’t be included in the results, which may or may not suit you.
It will make your life as a developer a lot easier to simply turn on snapshot isolation. In PostgreSQL, you don’t have to, because as I mentioned earlier: it won’t allow you to turn it off. But, in MSSQL, you really do have to. Yes, you do.
ALTER DATABASE YTEC_Test SET READ_COMMITTED_SNAPSHOT ON ALTER DATABASE YTEC_Test SET ALLOW_SNAPSHOT_ISOLATION ON
Welcome, MSSQL users, in the wonderful world of snapshot isolation! Now, let’s open WRITE1 again and retry READ1 and we’ll see that something wonderful has happened: we were able to read the data, including the row that was at that moment being updated.
That’s why turning on snapshot isolation can make a huge difference. If your legacy applications depend on MSSQL, it’s definitely worth testing them with snapshot isolation turned on. Snapshot isolation was first introduced in Microsoft SQL Server in 2005. That’s a long time for such an essential feature to go unused! I hope that Exact Software is listening and will announce official support for turning on snapshot isolation in Exact Globe’s database; then, eventually, they could even stop performing all their read operations at transaction isolation level READ UNCOMMITTED.
Finally, a quick word of advice: if you’re at the start of a new project and not yet stuck with a particular database legacy, I would recommend looking into PostgreSQL first. Changes are, you won’t ever look back. In a future article [on the now, as of 2024-03-20, extinct Ytec blog], I may go into the reasons why.
I was researching how TVs pass through audio coming in from HDMI, and I found this. Just dumping it here as memory.
I updated my personal homepage at the beginning of the new year. Some of the changes were long overdue, like my university student status and the number of diving licenses. But, there were other changes that arose from a more recent insight: that, if I am to reach my goals, I need a plan. A bad plan is better than no plan. And too many goals are as useless as no goals.
Here is my plan as I published it in Januari in verbatim:
This ♂ has a plan: to become a happy little 🐷. His tech job at YTEC already keeps him warm and his belly full. (His family 💰 and the 🇳🇱 welfare state helped him along the way.) 🐷 2 + 2 little 🐱🐱 + some 🌿🌴 make 🏠 🏠. And, with all that comfort, ❄️🚿🚿, योगः, 中国武术 and มวยไทย keep the 🐷 from getting 䏘.
Homo sapiens is more homonid than sapiens, so the most sapient thing for this H. to do is to take good care of his 🐒-mind. This 🐒 wants ♀
♀(☑), and is very particular about who he keeps ✓ed in this ☐—a ♀ who breaks out of the stupid ☐, and climbs on top of it to 👙💃.Outside this most private of private bubbles, there are friends and family on call to put into perspective the tribulations that flow from the oft-inflated need to earn societal respect and dominate other ♂♂. At his most ☮️ful, his work and hobbies (i.e., kickboxing & diving) afford him plenty of opportunity to ✓ this ☐, but sometimes he dreams of wider recognition, especially at times of narrow self-respect.
He used to want to grow 📈 indiscriminately in all directions at once (like a ♋), dreaming of universal admiration and acceptance, being unable to accept—let alone, love—himself. Having since undergone therapy, he can now make the 🐒 feel sufficiently secure to focus on more ☯ forms of self-improvement, as long as he pays conscious attention to his need for ♡.
2018’s goal is for him to learn to respect himself, which requires him to ⒜ be deserving of respect, and ⒝ to give himself credit when credit is due. To combat self-sabotage and improve his discipline, he has given himself 3 rules: ① consumption is production; ② the training schedule is sacred; and ③ meditate daily. This may sound harsh, and it is, if he will needlessly beat himself up over any failure to comply. These rules are fairly constant, but there’s also a maximum of 4 assignments, which will change when they’re finished or given up; currently, these 4 are: ⓐ publish
76 articles on Sapiens Habitat about PPPermaculture; ⓑ create an Angel prototype and share it with colleagues; ⓒ finish opschoot‘s Mint upgrade; and ⓓ remember 7 new lucid dreams.Note that there’s no need to work on these assignments; they don’t have a deadline. Deadlines abound in the day job. It’s all about the rule of ④: no more than 4 private projects at the time, to avoid all that free energy from being scattered with purpose nor satisfaction.
My adherence to rule ① has been decent in the beginning but is somewhat mixed at the moment: I’ve tweeted most times that I caught myself scrolling Twitter, but I haven’t written something—even if it’s just a single line—every time I’ve been mindlessly losing myself in the newspaper. Definitely, I need to continue to be vigilant if I want to rid myself of my habit to numb myself with mindless information consumption.
Speaking of production: For some time, I’ve waited with writing more about Annemarie, Laurelin and Nils their permaculture adventures in Portugal ⓐ while making some adjustments to the layout of sapienshabitat.com. But, I am now nicely progressing ⓐ with the second article in the series on PPPermaculture: Tree Nurse Nils.
Rule ② has been somewhat more sacred to me than rule ①, and I’m proud to say that I’ve persisted through quite a bit of boredom. Interestingly, so far, I’ve found adhering to my training schedule easier than making changes to it. The only changes I made were rather minor.
Last week, I decided that I want to pursue some competitive kickboxing bouts. But, that’ll have to wait until I finished one of ⓐ through ⓓ. Otherwise, I’d be violating the rule of ④.
Being mindful instead of running around like a caffeinated chicken is still challenging, in so far as that I don’t feel that I’ve further progressed towards being sufficiently at ease during the day that it has improved my dream content. My dream recall, however, has kind of improved.
There have been days on which I violated rule ③, and these shouldn’t be allowed to multiple. But, it’s also important to remember the spirit of the rule rather than the letter. And that spirit would soar as soon as ⓓ I will have the first of those 7 new lucid dreams.
The rule of ④ is great. It has already protected me from undertaking ⓔ and ⓕ before finishing ⓐ through ⓓ. It also has a motivating quality, because I’m really itching (literally) to try ⓔ a ketogenic diet again.
| Rule ① | Rule ② | Rule ③ | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Week | Su | Mo | Tu | We | Th | Fr | Sa | Su | Mo | Tu | We | Th | Fr | Sa | Su | Mo | Tu | We | Th | Fr | Sa |
| 17 | ⅖ | ⅖ | ⅖ | ⅖ | ⅖ | ⅖ | ⅖ | ☑ | ☐ | ☑ | ☑ | ☑ | ☑ | ☑ | ☑ | ☑ | ☑ | ☑ | ☑ | ☑ | ☑ |
| 18 | ⅔ | ⅔ | ⅔ | ⅔ | ⅔ | ⅔ | ⅔ | ☑ | ☑ | ☐ | ☑ | ☑ | ☐ | ☐ | ☑ | ☑ | ☑ | ☑ | ☑ | ☑ | ☑ |
| 19 | ⅔ | ⅔ | ⅔ | ⅔ | ⅔ | ⅔ | ☐ | ☐ | ☐ | ☑ | ☑ | ☑ | ☑ | ☐ | ☑ | ☑ | ☐ | ☑ | ☑ | ☐ | ☐ |
| 20 | ½ | ½ | ½ | ½ | ½ | ½ | ½ | ☑ | ☑ | ☐ | ☑ | ☐ | ☑ | ☑ | ☑ | ☑ | ☐ | ☑ | ☐ | ☑ | ☑ |
| 21 | I can not nor want to remember all this shit throughout the week. | ||||||||||||||||||||
| ⓐ published 5 of first 7 articles about PPPermaculture on sapienshabitat.com | |
| ⓑ create an Angel prototype and share it with colleagues | |
| ⓒ finished opschoot‘s Mint upgrade | ☑ on Feb. 22 2018 |
| ⓓ remembered 7 of 7 new lucid dreams | ☑ on Jun. 8 2018 |
| ⓔ tried a ketogenic diet again for a week | ☑ from Feb. 12–18 2018 |
| ⓕ fight a kickboxing match | started in the beginning Mar. 2018, officially paused at the end of Apr. |
| ⓖ publish opinion piece about the annual winter-time population crash in the Oostvaardersplassen | ☑ on Mar. 14 2018 |
| ⓗ submit an entry for the NRC essay writing competition | started on May 26 2018 ☑ on Jun. 25 2018 |
| ⓘ something something Magento | started on Jun. 8 2018 |
| ⓙ reviewing Myrna her open letter to the Dutch national Health Council | embarked on Jun 25. 2018 ☑ on Jul. 1 2018 |
| ⓚ sand and paint my bicycle cart | waiting for a slot |
| ⓜ get Hardwood wikis back online and put them up for sale | waiting for a slot |
| ⓝ redesign www.bigsmoke.us | accidentally started on Aug. 27 |
Just some quick links with the status of Spectre and Meltdown:
A long, long time ago, when I still thought that Drupal would turn out be a good choice for a new website project, I founded www.worldwidewilderness.com. Well, actually I found www.world-wide-wilderness.com, because I didn’t know that ‘worldwide’ is spelled as one word. And, then I found www.worldwide-wilderness.com, because I thought that hyphens in domain names are really cool—so cool, in fact, that I was on the Dashing Domains fanlist for years. Apart from all the hyphens, I still like the Worldwide Wilderness, so much so that I’ve recently been considering building an interactive map of all the remaining wilderness areas in the world under the brand.
Because of Rule 4—the rule of 4—I will not work on this idea any time soon, and the best way to get an idea out of my head is to put it on paper (of sorts): the idea is to have an interactive map of the world in which wilderness areas are marked according to the threats and protections that are present. Vetted specialist users should be able to amend this information and every site should include information about all the actions that concerned visitors can take to improve the protection of the wildernesses.
For archival purposes, below is the blurb I used to describe the project on www.bigsmoke.us:
I’m a wild ape and civilization is a bad joke I didn’t get the punchline of. Somehow I’m supposed to be excited about all the freedom that my ancestors didn’t have because they were too busy staying alive. I have to be grateful for all the stuff that I can fill my life with in the absence of the struggle for survival. Instead of hunger and hungry predators we have gotten a pack of paper predators chasing us through life. The whole pack is being digitized so that we can run even faster.
Constantly, I feel threatened, because I am supposed to feel threatened for things that are simply not threatening, no matter how you turn them around or blow them out of proportion. As a social animal, nog taking these “threats” serious does feel seriously threatening to my social status. But I’m taking my chances. Fuck you and your self-imposed cages! I do not agree to be lifestock. I claim the right to be the wild animal that I will be regardless of your (and my) attempts to control me.
Self-control is a delusion. Self-improvement is masturbation. Because who would be doing the controlling and who would be doing the improving? Not me, that’s for sure.
Because Windows doesn’t have dd, and I want to write the latest Mint LTS release to a USB task, I had to face the unpleasant task of finding a Windows tool to perform what’s a basic Unix operation. The good news is that I found one, and it’s open source: Win32 Disk Imager. It even has a version ≥ 1, titled: “Holy cow, we made a 1.0 Release”.
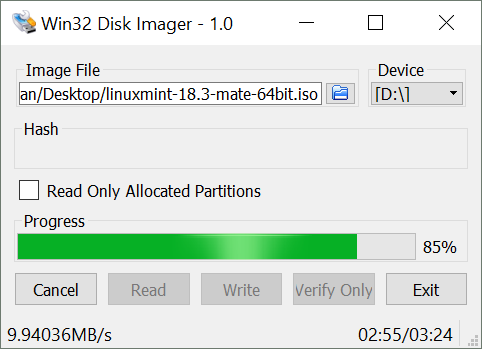
Win32 Disk Imager at work, writing Linux Mint 18.3 MATE 64bit to my SanDisk USB stick.
I found another open source tool, UNetbootin, but that tool didn’t recognize my non-MS-format formatted USB stick (which already tauted the installer for a previous Mint release).
In the end, Win32 Disk Imager also choked on the funky partition table left by the previous boot image, so I had to find out how reset the USB disk’s partition table in Windows:
C:\WINDOWS\system32>diskpart Microsoft DiskPart version 10.0.16299.15 Copyright (C) Microsoft Corporation. On computer: YTHINK DISKPART> list disk Disk ### Status Size Free Dyn Gpt -------- ------------- ------- ------- --- --- Disk 0 Online 238 GB 0 B * Disk 1 Online 29 GB 28 GB DISKPART> select disk 1 Disk 1 is now the selected disk. DISKPART> list partition Partition ### Type Size Offset ------------- ---------------- ------- ------- Partition 1 Primary 1706 MB 1024 KB Partition 2 Primary 2368 KB 1707 MB DISKPART> select partition 2 Partition 2 is now the selected partition. DISKPART> delete partition DiskPart successfully deleted the selected partition. DISKPART> select partition 0 The specified partition is not valid. Please select a valid partition. There is no partition selected. DISKPART> select partition 1 Partition 1 is now the selected partition. DISKPART> delete partition DiskPart successfully deleted the selected partition. DISKPART> create partition primary DiskPart succeeded in creating the specified partition. DISKPART> exit Leaving DiskPart... C:\WINDOWS\system32>
Just as a note to self mostly: this is an interesting article about the noise in a LM317/LM337 based power supply.
For Low ESR caps, one can use:
© 2026 BigSmoke
Theme by Anders Noren — Up ↑
Recent Comments